
 Spring循环依赖
Spring循环依赖
# 什么是循环依赖
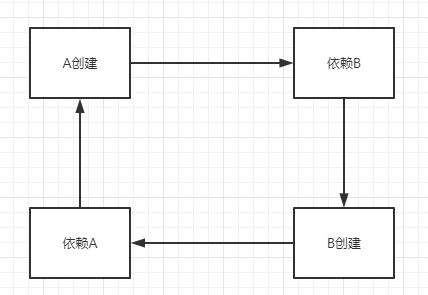
什么是循环依赖,如下图所示
A创建时--->依赖B---->B去创建--->依赖A,从而产生了循环
如何解决循环依赖,如下图所示可以引入一个缓存池来解决循环依赖的问题。
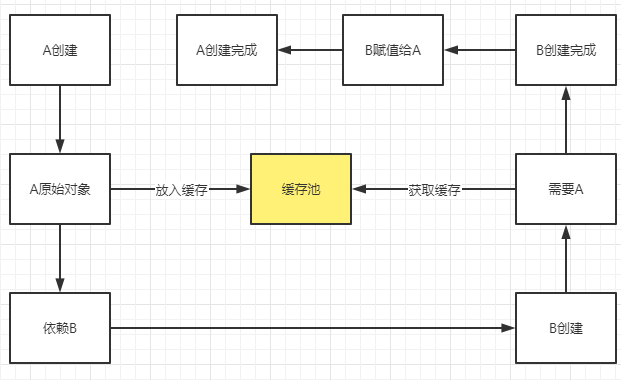
从上图可以看出 好像只需要一个缓存(二级缓存)就可以解决循环依赖,那么为什么Spring要设计第三级缓存(singletonFactories)呢。原因是Spring的AOP,如果一个类需要进行AOP生成代理对象,那么存到单例池(singletonObjects)中的就是代理对象,而代理对象是在spring生命周期的初始化后阶段产生的,而赋值属性的步骤是在其之前,那么存入缓存池的就不是代理对象,也就是说给B赋值的A对象不是代理对象,这就与Spring的涉及产生了冲突。
即 B依赖的A和最终的A不是同一个对象。
# 三级缓存
# singletonObjects(一级缓存:单例池)
缓存经过了完整生命周期的bean。
# earlySingletonObjects(二级缓存)
缓存未经过完整生命周期的bean,只要某个bean出现了循环依赖,就会提前把这个暂时未经过完整生命周期的bean放入earlySingletonObjects中(这个bean如果要经过AOP,那么就会把代理对象放入earlySingletonObjects中,否则就是把原始对象放入earlySingletonObjects),即使是代理对象,代理对象所代理的原始对象也是没有经过完整生命周期的。
# singletonFactories(三级缓存)
缓存的是一个Lambda表达式。在每个Bean的生成过程中,经过实例化得到一个原始对象后,都会提前基于原始对象暴露一个Lambda表达式,并保存到三级缓存中(这个Lambda表达式可能用到也可能用不到,如果当前Bean没有出现循环依赖,那么这个Lambda表达式没用)。如果当前bean在依赖注入时发现出现了循环依赖,则从三级缓存中拿到Lambda表达式,并执行Lambda表达式得到一个对象,并把得到的对象放入二级缓存。
# earlyProxyReferences
其实还要一个缓存,就是earlyProxyReferences,它用来记录某个原始对象是否进行过AOP了。
# 为什么需要第三级缓存
主要为了处理AOP的问题。
如果没有第三级缓存earlySingletonObjects,则每个bean在依赖注入之前都要去进行AOP的操作,不符合bean的生命周期步骤设计,即AOP对象是在初始化之后生成。
有第三级缓存,则没有循环依赖的需要AOP对象可以按bean的生命周期步骤进行,有循环依赖的需要AOP对象在依赖注入时通过三级缓存中Lambda表达式获取AOP对象放入二级缓存。初始化后要生成AOP对象时去判断是否已经生成过,已生成则不再处理。