
 Collections之Map&List&Set详解
Collections之Map&List&Set详解
# HashMap详解
# 数据结构
- JDK<8 : 数组+链表
- jdk>=8 : 数组+链表+红黑树(容量>=64 and 链表长度>8)
# 重要成员变量
DEFAULT_INITIAL_CAPACITY = 1 << 4; Hash表默认初始容量 16 必须是2的幂次方
MAXIMUM_CAPACITY = 1 << 30; 最大Hash表容量
DEFAULT_LOAD_FACTOR = 0.75f;默认加载因子
TREEIFY_THRESHOLD = 8;链表转红黑树阈值 > 8
UNTREEIFY_THRESHOLD = 6;红黑树转链表阈值 <=6
MIN_TREEIFY_CAPACITY = 64;链表转红黑树时hash表最小容量阈值,达不到优先扩容。
2
3
4
5
6
# 扩容机制
# JDK1.7
JDK1.7头插法扩容会导致死循环,头插法步骤如下
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;//第一行
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);//第二行
e.next = newTable[i];//第三行
newTable[i] = e;//第四行
e = next;//第五行
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 第一行:先记录旧数组的下一个节点
- 第二行:通过hash计算出在新数组的位置
- 第三行:把要入队的新元素指向 该位置的第一个元素
- 第四行:把入队的第一个元素设置为新元素
- 第五行:把下一个节点赋值为当前节点,继续循环处理
第三步+第四步 完成头插法
# 多线程扩容为什么会死循环?
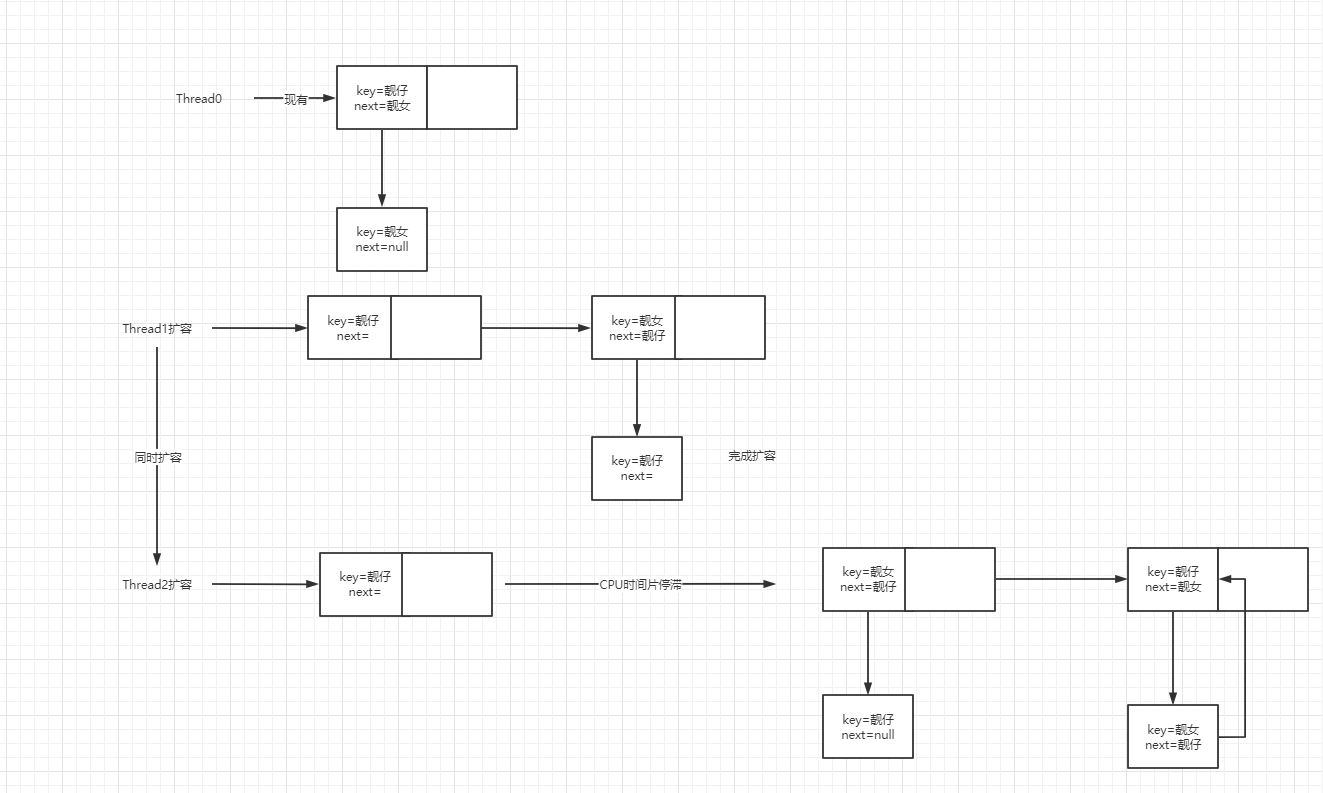
根据上图和头插法源码演示死循环
原始数组 指针指向: 靓仔-->靓女-->null
线程1和线程2同时扩容,都走到了 Entry<K,V> next = e.next;此时线程2让出CPU
线程1先完成扩容,此时数组 靓女-->靓仔-->null
线程2拿到时间片,第一次循环 靓仔->null
- 此时第2次循环, 靓女已经指向了靓仔,所以next != null 而是=靓仔,然后靓女入队:靓女->靓仔->null
- 由于next = 靓仔,所以靓仔又要重新入队 靓仔->靓女 即靓仔<-->靓女 互相指向。
- 当get时,触发靓仔靓女一直互相找,导致死循环。
# JDK1.8(尾插法)
# put方法解析
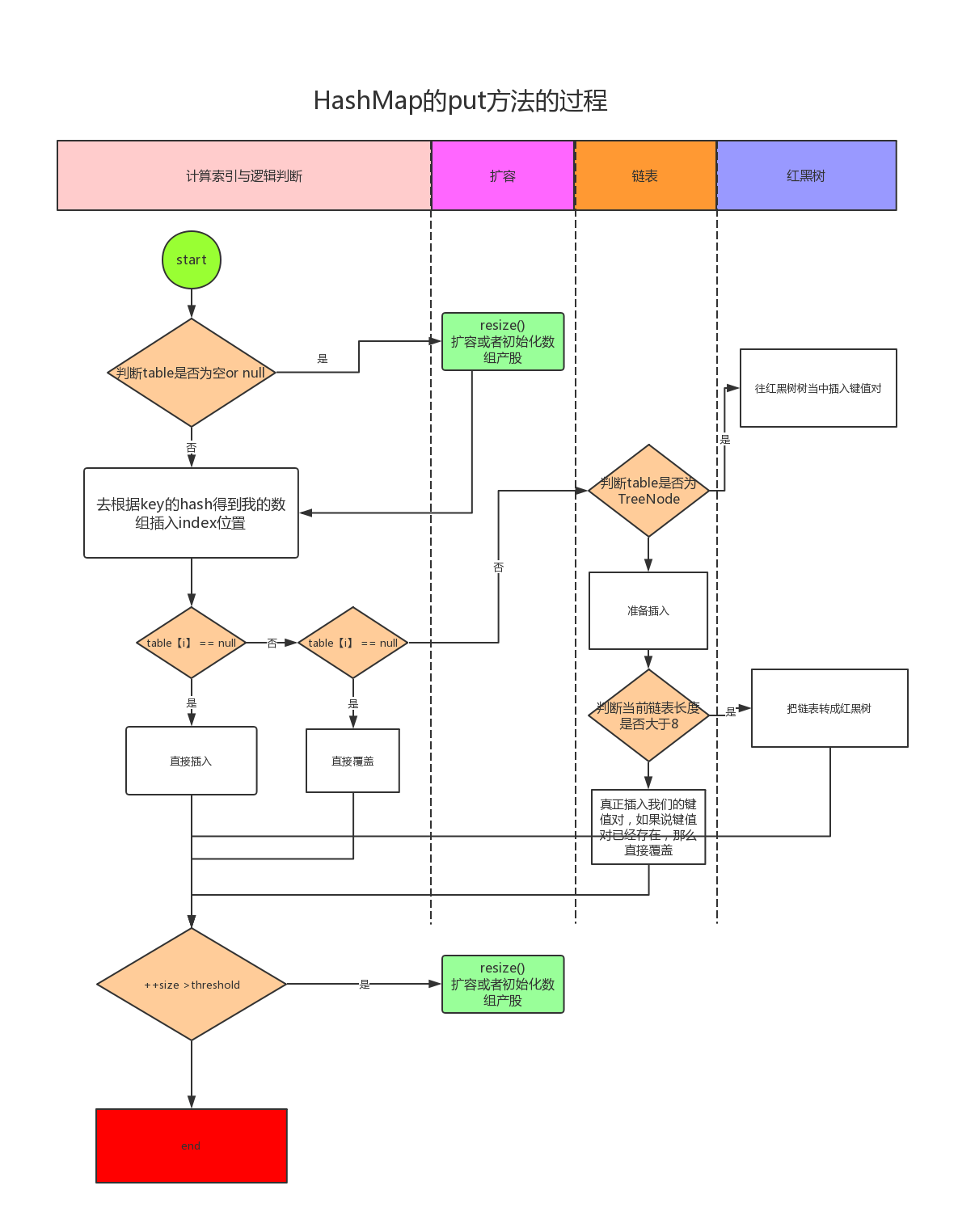
Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { //felix.hashcode & 16 = 0,用低位指针 if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { //felix.hashcode & 16 > 0 高位指针 if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead;,移到新的数组上的同样的index位置 } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; //index 3+16 = 19 }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30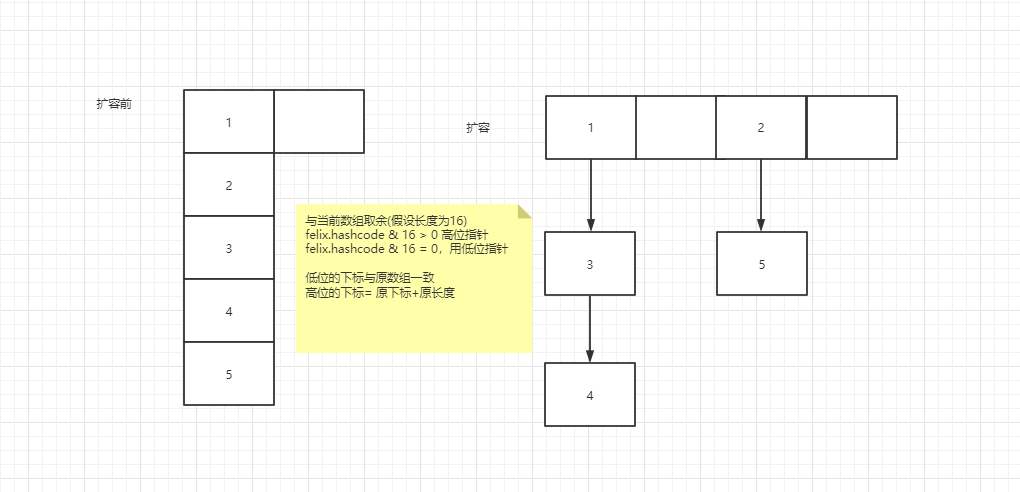
JDK1.8扩容时是基于高低位指针进行迁移
首先新增2倍的数组长度,然后通过hashcode & 旧的数组长度 如果是大于0,则按照 当前索引+旧的数组长度 迁移到新数组的高位
如果等于=0,则迁移到新数组的低位(也就是原数组的index)
# ConcurrentHashMap详解
# 数据结构
ConcurrentHashMap的数据结构与HashMap基本类似,区别在于:1、内部在数据写入时加了同步机制(分段锁)保证线程安全,读操作是无锁操作;2、扩容时老数据的转移是并发执行的,这样扩容的效率更高。
# 并发安全控制
Java7 ConcurrentHashMap基于ReentrantLock实现分段锁
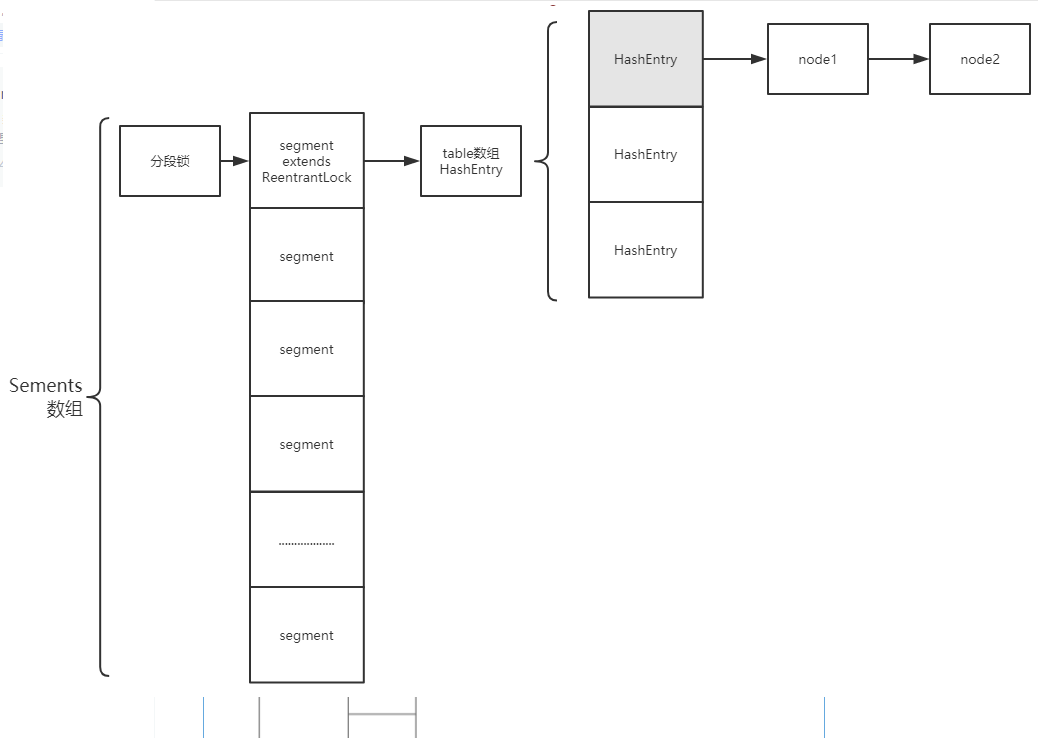
Java8中 ConcurrentHashMap基于分段锁+CAS保证线程安全,分段锁基于synchronized关键字实现;
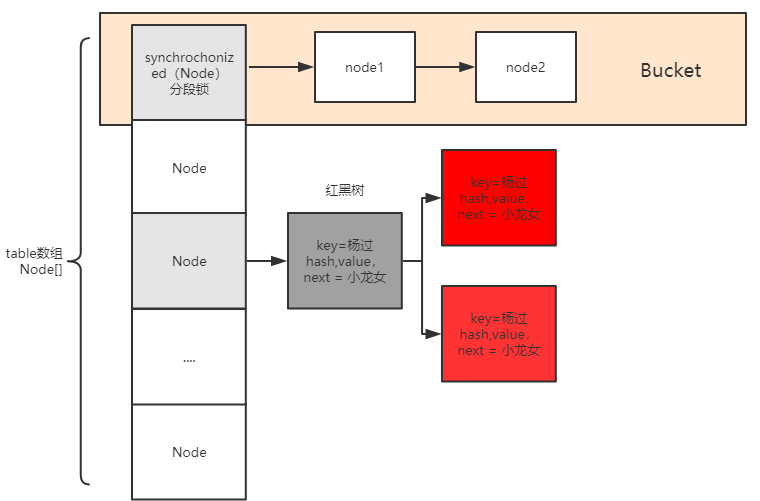
# 源码原理分析
# 重要成员变量
ConcurrentHashMap拥有出色的性能, 在真正掌握内部结构时, 先要掌握比较重要的成员:
LOAD_FACTOR: 负载因子, 默认75%, 当table使用率达到75%时, 为减少table的hash碰撞, tabel长度将扩容一倍。负载因子计算: 元素总个数%table.lengh
TREEIFY_THRESHOLD: 默认8, 当链表长度达到8时, 将结构转变为红黑树。
UNTREEIFY_THRESHOLD: 默认6, 红黑树转变为链表的阈值。
MIN_TRANSFER_STRIDE: 默认16, table扩容时, 每个线程最少迁移table的槽位个数。
MOVED: 值为-1, 当Node.hash为MOVED时, 代表着table正在扩容
TREEBIN, 置为-2, 代表此元素后接红黑树。
nextTable: table迁移过程临时变量, 在迁移过程中将元素全部迁移到nextTable上。
sizeCtl: 用来标志table初始化和扩容的,不同的取值代表着不同的含义:
- 0: table还没有被初始化
- -1: table正在初始化
- 小于-1: 实际值为resizeStamp(n)<<RESIZE_STAMP_SHIFT+2, 表明table正在扩容
- 大于0: 初始化完成后, 代表table最大存放元素的个数, 默认为0.75*n
transferIndex: table容量从n扩到2n时, 是从索引n->1的元素开始迁移, transferIndex代表当前已经迁移的元素下标
ForwardingNode: 一个特殊的Node节点, 其hashcode=MOVED, 代表着此时table正在做扩容操作。扩容期间, 若table某个元素为null, 那么该元素设置为ForwardingNode, 当下个线程向这个元素插入数据时, 检查hashcode=MOVED, 就会帮着扩容。
ConcurrentHashMap由三部分构成, table+链表+红黑树, 其中table是一个数组, 既然是数组, 必须要在使用时确定数组的大小, 当table存放的元素过多时, 就需要扩容, 以减少碰撞发生次数, 本文就讲解扩容的过程。扩容检查主要发生在插入元素(putVal())的过程:
- 一个线程插完元素后, 检查table使用率, 若超过阈值, 调用transfer进行扩容
- 一个线程插入数据时, 发现table对应元素的hash=MOVED, 那么调用helpTransfer()协助扩容。